


Introducción
- ¿Qué es el Data Engineering?
- El perfil de Ingeniería de Datos
- Big Data
- Las herramientas del Data Engineer
- ¿Dónde capacitarse?
- Recursos gratuitos
- Recursos de pago
- Conclusión
En mayo de este año, unos meses después de haber comenzado en mi primer trabajo, decidí reorientar mi camino profesional hacia una rama muy interesante, relativamente “joven” y que se encuentra en demanda creciente: Data Engineering.
Donde me encuentro trabajando actualmente realizo integraciones de datos y procesos ETL. No voy a ahondar (todavía) en qué es un ETL, pero básicamente es tomar datos desde una fuente y transformarlos en algo distinto para que luego estos datos solucionen las necesidades de quien consuma dichos datos. Cuando apenas comencé a trabajar todo esto me resultaba muy novedoso: no tenía idea de qué era un ETL y para mi el concepto de “Data” se reducía a estructuras de datos. Es más, no tenía ni idea de la diferencia entre los distintos roles en data. Solo asumía que era un rubro muy difícil y poco interesante ya que había que pasársela haciendo gráficos (sí, así de ignorante era).
A medida que pasaron los meses empecé a participar de más proyectos donde el patrón se repetía: hay una fuente de datos (un Excel, una base de datos, una API, etc), y hay alguien que necesita que esos datos cambien, que resuelvan una necesidad en base a ciertas reglas de negocio y que esos datos “fluyan” con cierta frecuencia. Así, sin darme cuenta, ya estaba encargándome de una “patita” de lo que se conoce como Ingenieria de Datos.
Antes de comenzar en este puesto laboral yo ya tenía conocimientos de backend en general, de Python y también tenía nociones sobre bases de datos. Data Engineering se solapa con esta área del desarrollo, por lo que si bien dar mis primeros pasos tuvo su cuota de fricción, me sorprendió lo bien que me terminé adaptando en relativamente poco tiempo. Hoy no me considero un experto en estos conocimientos, pero he avanzado bastante.
Fiel a mi forma de ser, no me bastaba con cumplir con los proyectos y listo. Quería saber más, quería entender mejor el proceso que hago a diario para poder refinarlo y perfeccionarlo. Muchas cosas en la vida se relacionan con modelos mentales, y, en mi caso, quería y quiero tener el modelo mental de un Ingeniero de datos. Puse manos a la obra, busqué recursos, me anoté en Datacamp y comencé a indagar.
Este post es el resultado de estos meses de estudio sobre el tema y es el primero de varios que espero publicar en el tiempo sobre Data Engineering. No solo me sirve de repaso para estudiar, sino que también quiero que tú, quien está leyendo estas líneas, sepas qué es y qué NO es Data Engineering. Quién sabe, quizás te convierto al lado oscuro (o quizás pueda contribuir con mi granito de arena a que tomes una decisión si es que estás evaluando un cambio profesional). Comencemos.
1. ¿Qué es Data Engineering?
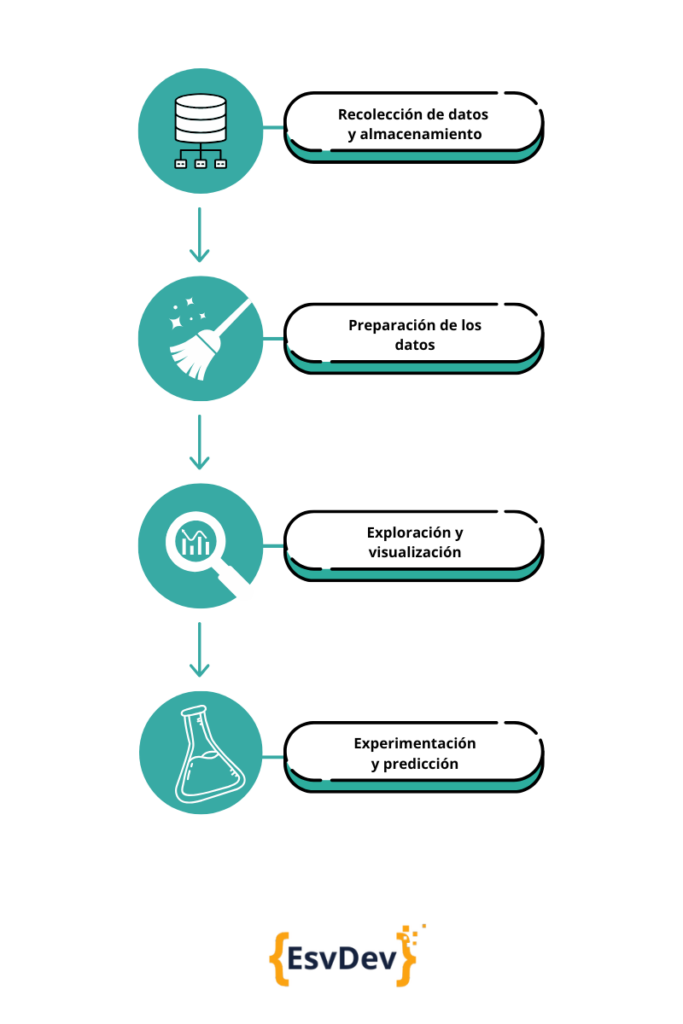
Para comprender de qué se trata este campo dentro del ecosistema de Data, primero tenemos que hablar del ciclo de vida de los datos. Existen cuatro pasos generales por los cuales los datos fluyen en una organización.
- Primero, se recolectan e ingieren datos de distintas fuentes, como lo puede ser una encuesta, tráfico web, etc. Todos estos datos se almacenan en estado “crudo”, sin ninguna clase de procesamiento o modificación.
- El próximo paso es preparar estos datos, lo que incluye la “limpieza de datos”, es decir, encontrar valores perdidos o duplicados y convertir toda esta información a un formato más organizado, entre otras cosas.
- Una vez que los datos están limpios y organizados, pueden ser explotados. Por ejemplo, pueden ser explorados, visualizados mediante dashboards para seguir cambios, o también para realizar comparaciones entre distintos conjuntos de datos (datasets).
- Finalmente, una vez se tiene un buen entendimiento de los datos, estamos listos para realizar experimentos, como por ejemplo evaluar qué artículo tuvo la mayor cantidad de clicks, o cuál fue la canción más escuchada. También podemos construir modelos predictivos para, por ejemplo, predecir los valores de ciertas acciones en la bolsa.
Data Engineering, y quien la ejerce, el/la Data Engineer, se encargan del primer paso de este ciclo.
👉🏻 Según el libro Fundamentals of Data Engineering de Joe Reis & Matt Housley, esta es la definición de lo que es Data Engineering:
”Data Engineering es el desarrollo, implementación y mantenimiento de sistemas y procesos que reciben data en formato ‘crudo’ y producen información consistente y de alta calidad que satisface casos de uso posteriores como el análisis o machine learning.
Un Data Engineer gestiona el ciclo de vida de la Ingenieria de Datos, comenzando con obtener datos de sistemas fuente y finaliza con servir estos datos para los casos de uso correspondientes.
Este profesional suele actuar como un puente entre productores de datos, como Ingenieros de Software, Arquitectos de Datos y SREs, y consumidores de datos, tales como Analistas de Datos, Científicos de Datos e Ingenieros de Machine Learning”.
2. El perfil de Ingeniería de Datos
Como dijimos, los Ingenieros de Datos son responsables del primer paso del proceso descrito anteriormente: ingerir y almacenar datos. Estos profesionales tienen una gran responsabilidad ya que establecen los fundamentos sobre los cuales los Analistas de Datos, Científicos de Datos e Ingenieros de Machine Learning realizan su trabajo. Si los datos se hallan dispersos o desorganizados, corrompidos o no es fácil acceder a ellos, no hay mucho que preparar, explorar y por lo tanto, no hay mucho (o nada) con lo que experimentar adecuadamente.
Un Ingeniero de Datos se encarga de entregar:
- los datos correctos
- en la forma correcta
- a la gente correcta
- de la manera más eficiente posible
Entre sus distintas responsabilidades se encuentran:
- Ingerir datos desde distintas fuentes
- Optimizar bases de datos para análisis
- Eliminar datos corrompidos
- Desarrollar, construir, testear y mantener arquitecturas tales como bases de datos y sistemas de procesamiento de gran escala encargados de gestionar enormes cantidades de datos
- Construir pipelines de datos automatizados que aseguran que los datos fluyan de manera continua, desde la fuente hasta el destino (como un warehouse o un dashboard) en tiempo real o casi en tiempo real
- Procesar grandes cantidades de datos mediantes enfoques como ETL (Extract Transform Load) y ELT (Extract Load Transform)
🙅♂️ ¿Qué cosas no hace este perfil? Típicamente, no construye modelos de Machine Learning de manera directa, no crea reportes ni visualizaciones o dashboards. Tampoco realiza análisis sobre los datos, no construye indicadores claves de performance (KPI) ni desarrolla aplicaciones de software. Sin embargo, un Ingeniero de Datos debería tener una comprensión funcional de dichas áreas para ser lo más efectivo posible.
3. Big Data
El último punto dentro de las responsabilidades que tiene un Data Engineer habla sobre “gestionar enormes cantidades de datos”. Cuando hablamos de cantidades enormes de información, no hablamos de otra cosa que Big Data. Existen conjuntos de datos tan grandes, que es obligatorio pensar cómo lidiar con su tamaño, ya que es difícil o incluso imposible procesar estos datos utilizando los métodos tradicionales de gestión de datos.
Ordenado por volumen, este tipo de data se compone de:
- Datos provenientes de sensores y dispositivos
- Datos originados en las redes sociales
- Datos corporativos
- VoIP (comunicación por voz, sesiones multimedia, etc)
Es importante que la Ingeniera de Datos tenga en cuenta los siguientes factores al momento de lidiar con Big Data. Estos factores son conocidos como “las 5 V”:
- Volumen (¿cuánto?) – La cantidad de data points
- Variedad (¿de qué tipo?) – El tipo y naturaleza de los datos, ya sean imágenes, video, audio, texto, etc
- Velocidad (¿con qué frecuencia?) – La rapidez con la que los datos son generados y procesados
- Veracidad (¿cuán precisos?) – Cuán confiables las fuentes de datos son
- Valor (¿qué tan útiles?) – Cuán accionables son los datos
4. Las herramientas del Data Engineer
Ahora que sabemos básicamente qué es lo que hace un/a Data Engineer, hablemos sobre los conocimientos técnicos que es importante adquirir para desempeñarse con éxito en este campo. Un Ingeniero de Datos debe entender y conocer las mejores prácticas en lo que se refiere a gestión de datos y tener una buena comprensión de lo que es Ingeniería de Software. Tal es así, que un Data Engineer que no sea capaz de escribir código de calidad para producción se encontrará severamente obstaculizado. Como dice el libro citado anteriormente, “los Ingenieros de Datos siguen siendo Ingenieros de Software, en adición a sus muchos otros roles”.
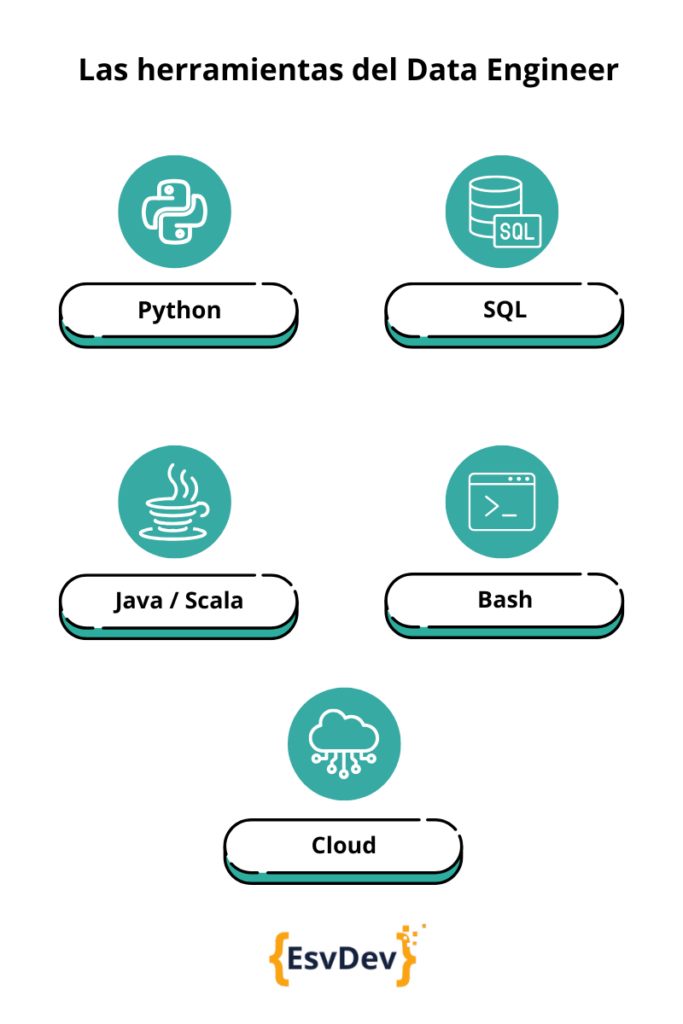
Dentro de los conocimientos técnicos indispensables, podemos destacar los siguientes:
- SQL: indispensable para crear y gestionar bases de datos y data lakes
- Python: definido como el lenguaje “puente” entre Data Engineering y Data Science. Un número creciente de herramientas para Ingenieria de Datos están escritos en Python o disponen de una API que sirve de interfaz con este lenguaje, tales como pandas, NumPy, Airflow, sci-kit learn, TensorFlow, PyTorch y PySpark
- Java / Scala: estos lenguajes que se ejecutan en la máquina virtual de Java (JVM) son beneficiosos al momento de utilizar frameworks de data que sea open source, tales como Apache Spark, Hive, Druid y Beam
- Bash: la interfaz de línea de comandos para sistemas operativos basados en Linux. Conocer comandos bash y estar cómodos al usar CLIs puede mejorar la productividad cuando es necesario crear scripts o realizar operaciones a nivel del sistema operativo. También es útil para utilizar herramientas como awk o sed
- Cloud Computing: Con el crecimiento exponencial de los datos, la computación en la nube se ha vuelto esencial para la Ingeniería de Datos. Con plataformas como AWS, Azure y Snowflake, los Ingenieros de Datos pueden gestionar grandes volúmenes de datos de forma escalable y rentable. Los servicios en la nube permiten configurar infraestructuras complejas con servicios como AWS Lambda para ejecutar código en respuesta a eventos, RDS para bases de datos relacionales, y Snowflake para almacenamiento y procesamiento de datos optimizados. Estas herramientas ayudan a simplificar la administración de datos y la implementación de soluciones de Big Data.
Si bien estas competencias técnicas sirven para construir una base sólida en este campo, puede ser necesario familiarizarse con otros lenguajes como R, Go, Rust, C/C++ o incluso C# y Powershell si la compañia donde trabajemos se desempeña en un ecosistema de Microsoft o utilice Azure.
Ahora bien, existen ciertas habilidades que, junto a las técnicas, son importantes que desarrollemos para ser un Data Engineer competente, entre las que se pueden destacar:
- Comunicarse con personas técnicas y no técnicas: es importante ganarse la confianza de las personas que componen la organización donde nos desempeñemos, aprendiendo las jerarquías de dicha organización, quién responde a quién, cómo interactúan las personas, etc. La comunicación es clave. El éxito o el fracaso rara vez es un problema relacionado con la tecnología
- Recolectar requerimientos del negocio/producto: es vital saber qué construir y asegurarnos de que las partes interesadas en el proyecto están de acuerdo con nuestro análisis o evaluación. Adicionalmente, debemos desarrollar un sentido de cómo los datos y las decisiones con respecto a la tecnología pueden impactar el negocio
- Calcular costos: un buen Data Engineer sabe cómo optimizar costos, ya sea optimizando el tiempo para generar valor, el costo de oportunidad e incluso sabe monitorear costos para evitar sorpresas (sobre todo al manejarnos con servicios en la nube)
- Aprendizaje continuo: Data es un campo que cambia velozmente. La gente que tiene éxito en este rubro es buena en integrar conceptos nuevos mientras refinan su conocimiento fundamental. También son buenos filtrando, determinando qué nuevas tecnologías o desarrollos son relevantes, cuáles aún son inmaduros y cuáles son en realidad modas pasajeras
5. ¿Dónde capacitarse?
Ahora que sabemos en líneas generales qué hace un Ingeniero de Datos y qué conocimientos necesita para desempeñarse eficientemente, resta preguntarnos dónde podemos obtener dichos conocimientos. Para la fecha de publicación de este post, no he encontrado ninguna oferta de educación formal orientada completamente a lo que es Data Engineering. Si bien existen carreras sobre Ciencia de Datos e Inteligencia Artificial, no he visto que los diferentes planes de estudio cubran a cabalidad todos los temas que se relacionan directamente con la posición en sí.
Sin embargo, existen muchos recursos (gratuitos y pagos) que nos permitirán adentrarnos en este campo. Te dejo algunos a continuación para que los consideres y, si crees que me falta algo, te invito a que me contactes así lo agrego a la lista.
6. Recursos gratuitos
- Start Data Engineering: si bien no es una plataforma de cursos, es un buen sitio donde se suelen compartir con regularidad publicaciones, tutoriales y noticias para estar al tanto de las novedades del campo. Además podés anotarte a su newsletter donde te comparten contenido de calidad directo a tu casilla de correo.
- Data Engineering Roadmap en español: repositorio de GitHub con un roadmap o guía con los diferentes temas a cubrir para iniciarte en Ingeniería de Datos, cortesía de la genial natayadev, una Ingeniera de Datos SR con quien tengo el gusto de hablar con frecuencia, solicitarle consejos y hasta tuvo la gentileza de revisar el boceto de este post, haciendo correcciones y revisiones. El repositorio está dividido por temas y contiene muchísimos enlaces a videos y tutoriales para que puedas aprender de manera gratuita. Hasta hay una carpeta con distintos libros en formato PDF, de los cuales recomiendo fuertemente “Fundamentals Of Data Engineering”, gran obra que ha servido de fuente principal para escribir este artículo.
7. Recursos de pago
- Datacamp: excelente plataforma orientada a las distintas profesiones que existen en el ecosistema de Data, como así tambien campos relacionados como el Machine Learning y Cloud Computing. Podrás encontrar muchísimos cursos, que van desde SQL (básico, intermedio, avanzado), pasando obviamente por Python, hasta introducción a AWS e incluso Java. Algo que destaco de esta plataforma son la cantidad de ejercicios que te proponen realizar (en forma de quizzes o ejercicios con código) entre clase y clase. Pero lo más destacado de todo, son los tracks: rutas de estudios creadas específicamente para que puedas obtener un trabajo en cierto rol. De estos, existen dos que nos atañen, el Associate Data Engineer in SQL y Data Engineering in Python. Te invito a que examines los temas que abarcan y me digas si no te dan ganas de sumergirte a pleno. Te libran de todo lo que involucra organizar los distintos contenidos, permitiéndote que te adentres de lleno en el proceso de aprendizaje.
8. Conclusión
La Ingeniería de Datos es la columna vertebral en el ecosistema de datos, responsable de transformar datos en bruto en información accesible y confiable para los equipos de Análisis, Ciencia de Datos y Machine Learning. Desde la ingesta y almacenamiento de datos hasta la creación de arquitecturas robustas y pipelines eficientes, los Ingenieros de Datos establecen la base para extraer valor de grandes volúmenes de información.
En la era de la Inteligencia Artificial y el Big Data, la importancia de la Ingeniería de Datos ha crecido exponencialmente. Las organizaciones de todos los sectores confían en estos profesionales para gestionar de forma eficaz enormes cantidades de datos y facilitar el acceso a información precisa, lo que permite tomar decisiones informadas y desarrollar modelos predictivos avanzados. Con la continua expansión de la IA y el aprendizaje automático, el rol de los Ingenieros de Datos seguirá siendo fundamental, impulsando la innovación y el desarrollo de tecnologías que transforman el mundo.Ahora, dime: ¿estás listo/a para comenzar a aprender?




