



Índice
1. Introducción
En el artículo de hoy hablamos de la extensión Power BI Modeling MCP Server para Visual Studio Code y, después de pasar varias horas/días probándola sin piedad, tengo esa impresión que solo he tenido unas pocas veces en mi carrera: la de estar viendo algo que cambia el terreno de juego.
No es entusiasmo superficial. Es esa intuición técnica que se activa cuando entiendes las implicaciones de fondo.
Lo primero que hice fue leer qué es exactamente eso de MCP, Model Context Protocol. La definición oficial habla de estándares abiertos, de integración coherente con modelos de lenguaje, de exponer herramientas y contexto a LLMs.
Muy correcto todo.
Pero yo necesitaba aterrizarlo.
Porque una cosa es la teoría y otra muy distinta es lo que ocurre cuando tienes delante un modelo con cientos de millones de filas, relaciones dudosas y medidas heredadas de varias generaciones de desarrolladores.
Un MCP, en la práctica, es un mecanismo que permite exponer el modelo semántico completo —estructura, metadatos, lógica— a un agente de IA de forma estructurada y accionable. No es simplemente “consultar” el modelo. Es permitir que el agente lo entienda y pueda operar sobre él bajo reglas claras.
Y aquí está el punto clave: contexto real.
2. Caso práctico
Hasta ahora podíamos generar DAX con asistentes. Podíamos documentar TMDL con ayuda de Copilot. Pero aquí el agente no está trabajando con texto aislado. Está trabajando con el modelo vivo.
Eso, conceptualmente, es un salto enorme.
Me esperaba algún proceso complejo a la hora de instalarlo. Alguna configuración pesada. Pero no. Instalas la extensión en VS Code, activas el modo Agente y te conectas al modelo abierto en Microsoft Power BI Desktop.
Y ahí empieza la historia.
Abrí un modelo completamente limpio. Sin relaciones. Sin medidas. Nada que pudiera “maquillar” el resultado.
Desde VS Code lancé el prompt de conexión. Acepté permisos. Confirmé.
Y apareció el mensaje: conectado correctamente al modelo.
Ese instante es curioso. Porque sabes que no estás trabajando sobre un archivo plano. Estás interactuando con la estructura interna del modelo semántico.
No con una copia. Con el modelo.
La primera prueba fue casi instintiva: “Crea las relaciones del modelo”.
Confirmé los cambios.
Volví a Power BI.
Ahí estaban.
Relaciones correctamente establecidas, cardinalidades adecuadas, dirección de filtro lógica. No era una aproximación superficial. Era una creación coherente basada en la estructura existente.
Y lo más impactante no fue la velocidad. Fue la naturalidad.
- No tuve que abrir la vista de modelo.
- No tuve que arrastrar columnas.
- No tuve que revisar tabla por tabla.
Simplemente describí lo que quería. En ese momento no pensé “qué cómodo”. Pensé: “Vale, esto cambia la interacción”.
Después quise probar algo menos espectacular pero más cotidiano: traducciones masivas.
Si has trabajado con modelos corporativos sabes que traducir columnas y medidas puede convertirse en una tarea tediosa, mecánica y propensa a errores.
Le pedí que tradujera todas las columnas. Y lo hizo. Sin intervención manual. Sin tener que recorrer el modelo entero.
Es el tipo de mejora que no luce en una demo, pero que te ahorra horas de trabajo.
A continuación, le pedí que generara medidas y que las documentara correctamente.
Me devolvió DAX coherente, estructurado y con descripciones detalladas. Aquí la diferencia no es solo técnica. Es conceptual.
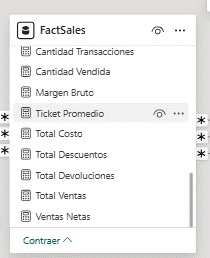
No estoy pidiendo que complete una fórmula. Estoy pidiendo que entienda el modelo y genere lógica alineada con su estructura. Y eso se nota.
Pero si quieres evaluar de verdad una herramienta, no la pruebas en un escenario perfecto. La pruebas en uno incómodo.
Modelo con una única tabla plana.
La típica sábana donde conviven métricas, fechas, productos y clientes en el mismo espacio. Le pedí que actuara como experto en modelado dimensional. Que construyera un esquema en estrella siguiendo Kimball. Que todo se generara en Power Query (M), sin recurrir a columnas calculadas DAX para estructurar el modelo.
Y empezó a trabajar.

- Extrajo dimensiones.
- Creó claves sustitutas.
- Preservó claves naturales.
- Generó jerarquías en la tabla de fechas.
- Aplicó limpieza de atributos.
- Definió relaciones activas Many-to-One.
- Ocultó la tabla origen.
Cuando terminó, el modelo ya no era una tabla plana. Era un modelo dimensional coherente.
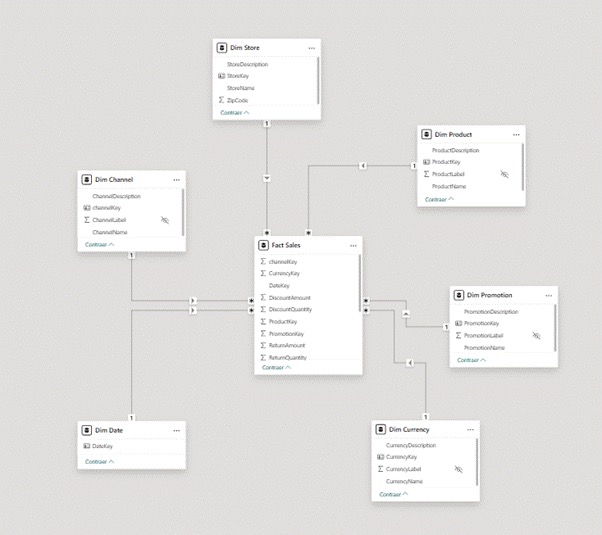
Ese fue el momento en el que dejé de verlo como una curiosidad tecnológica. Empecé a verlo como automatización real de modelado.
Pero aún faltaba la prueba de estrés. Modelo de Contoso con 237 millones de filas. Casi 7GB. Escenario realista, no académico.
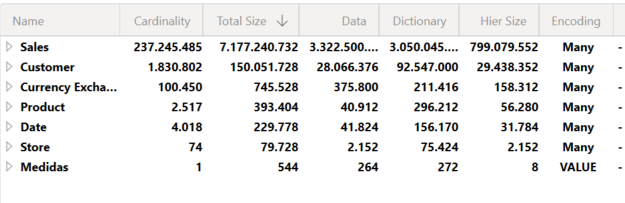
Le pedí que analizara tablas, relaciones y medidas y que me indicara mejoras siguiendo buenas prácticas.
En menos de medio minuto devolvió un diagnóstico detallado.
Señaló que la tabla Date no estaba marcada como tabla de fechas. Detectó medidas ineficientes. Clasificó recomendaciones por urgencia.
Las validé manualmente y tenía razón.
Le pedí que actuara sobre lo urgente. Aquí aprendí algo importante: si no eres preciso, la IA toma decisiones literales. Eliminó medidas en lugar de optimizarlas. No fue un fallo. Fue una interpretación literal de mi instrucción.
- Reformulé el prompt.
- Aplicó optimizaciones.
- Medí con DAX Studio.
El tiempo total de ejecución casi se redujo a la mitad. Menos consultas generadas. Menor tiempo en Storage Engine.
Antes:
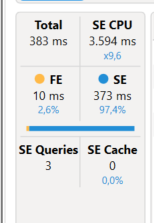
Después:

Y estamos hablando de un modelo grande. Ahí entendí que no era un asistente simpático. Era una herramienta capaz de impactar en rendimiento real.
Pero lo que realmente me dejó pensando fue la conexión directa al modelo en el servicio.
- Nada de descargar PBIX.
- Nada de trabajar en local.
- Conexión directa al modelo alojado.
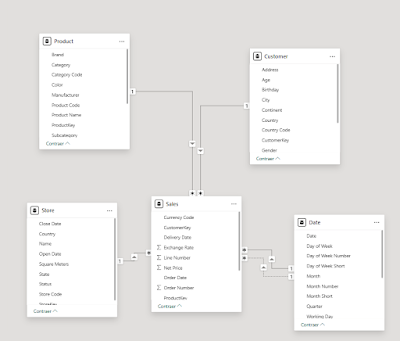
Le pedí que modelara en estrella desde una tabla plana alojada en el servicio. Y lo hizo.
- Generó dimensiones conformadas.
- Claves SK y NK.
- Relaciones activas.
- Jerarquías.
- Ocultación de la tabla origen.
Todo directamente sobre el modelo en la nube. Ese fue el momento en el que pensé: “Esto ya no es una mejora incremental. Es un cambio estructural”.
Cuando terminé de probar todo —relaciones automáticas, modelado en estrella, optimización de medidas, conexión directa al servicio— cerré VS Code y me quedé unos minutos mirando la pantalla en negro.
No con euforia.
Con silencio.
Porque lo que acababa de ver no era simplemente “hacer lo mismo más rápido”. Era otra cosa.
Durante años hemos trabajado el modelo semántico casi de manera artesanal. Arrastrar columnas. Crear relaciones. Escribir medidas. Revisar rendimiento. Documentar. Ajustar. Volver a medir. Todo con nuestras manos, con nuestro criterio, con nuestra experiencia acumulada a base de errores y aciertos.
Y de repente, estamos dialogando con el modelo.
No escribiendo instrucciones frías. No editando metadatos aislados. Dialogando.
Eso cambia la sensación de control. No la elimina. La transforma.
3. Conclusión
La IA aquí no es un atajo irresponsable. No es un botón mágico que hace “cosas”. Es un ejecutor extremadamente rápido de decisiones que siguen siendo tuyas. Si el prompt es impreciso, el resultado será impreciso. Si el criterio es débil, el modelo seguirá siendo débil. Pero si el criterio es sólido, la velocidad se multiplica.
Y eso es lo verdaderamente disruptivo.
Porque durante mucho tiempo el cuello de botella no ha sido el conocimiento, sino el tiempo. Sabíamos lo que había que hacer. Sabíamos que esa medida era ineficiente. Sabíamos que esa tabla debía ser dimensión y no hecho. Sabíamos que ese modelo necesitaba una jerarquía bien definida. Lo que faltaba era el tiempo para hacerlo todo con el nivel de detalle que queríamos.
Ahora el tiempo empieza a comprimirse. No desaparece la necesidad de pensar. Al contrario, se vuelve más importante. Pero la ejecución deja de ser el peso principal. Empieza a importar más la claridad con la que defines lo que quieres que ocurra.
Y ahí está el verdadero cambio de rol. De ejecutores manuales a supervisores técnicos. De constructores paso a paso a arquitectos que describen la estructura y validan el resultado.
Eso no es una moda. Eso es evolución natural cuando una tecnología madura lo suficiente como para integrarse en el flujo real de trabajo.
Lo que hemos visto no es una demo bonita. Es una señal de hacia dónde se mueve el desarrollo de modelos en Power BI. Modelos más colaborativos. Más automatizados. Más auditables. Más rápidos de iterar.
Pero también más exigentes en pensamiento crítico. Porque si la máquina puede ejecutar en segundos lo que antes tardábamos horas, entonces el valor ya no está en la ejecución. Está en la decisión. Y esa parte sigue siendo humana.
Si esto es el punto de partida, no quiero imaginar cómo será cuando esta integración esté más pulida, más extendida y más integrada en los procesos de equipo.
No estamos ante una funcionalidad más. Estamos ante el principio de una nueva forma de trabajar con modelos semánticos. Y cuando algo cambia la forma en la que trabajas, no es una mejora incremental.
Es un punto de inflexión.
Nos vemos en los datos.



