Índice
1. Introducción
AWS Bedrock es un servicio gestionado por Amazon Web Services (AWS) diseñado para simplificar el uso y la implementación de modelos de machine learning, especialmente grandes modelos de lenguaje (LLMs).
Este servicio permite acceder tanto a modelos de machine learning como de deep learning preentrenados y personalizarlos según el caso de uso (generación de texto, imágenes, audio…) sin necesidad de gestionar la infraestructura subyacente, como cualquier otro servicio ofrecido por AWS.
Bedrock resuelve varios problemas relacionados con el desarrollo de aplicaciones de IA generativa, donde FM indica Foundation Model:

Bedrock proporciona principalmente las siguientes ventajas:
Acceso a catálogo de modelos fundacionales del estado del arte
AWS Bedrock proporciona acceso a modelos avanzados de lenguaje natural que han sido preentrenados en grandes cantidades de datos. Estos modelos pueden ser fácilmente personalizados para adaptarse al lenguaje y terminología específicos del dominio para el que se implemente, como la documentación propia de una empresa o literatura médica como es el caso de Med-PaLM2, de Google.
Esto es posible ya que esta personalización se hace sobre los modelos fundacionales actuales en el estado del arte, para diferentes tareas de machine learning. La tarea más popular actualmente es la de generación de texto. Para ello AWS trabaja con partners como Antrophic, OpenAI, AI21 Labs o Stability AI, que proporcionan familias de modelos fundacionales dentro de la plataforma de Amazon, facilitando la interoperabilidad entre ellos.

Infraestructura gestionada y escalable
Como todo servicio cloud proporcionado por AWS, Bedrock ofrece una infraestructura totalmente gestionada, eliminando la necesidad de la administración de servidores, escalabilidad, mantenimiento, etc. Sin que se vea afectado el rendimiento del modelo, simplemente nos encargaremos de la tarea a resolver.
Implementación de la técnica RAG (Retrieval-Augmented Generation)
El principal beneficio AWS Bedrock es la implementación de la técnica conocida como RAG. Combina la generación de texto con la recuperación de información de una base de conocimiento o base de datos vectorizada. Este enfoque se utiliza para mejorar la precisión y la relevancia de las respuestas generadas por los grandes modelos de lenguaje teniendo el cuenta un contexto y conocimiento específicos.
La principal ventaja que aporta este enfoque, y que ha provocado una revolución en el campo del procesamiento del lenguaje natural, y en el entrenamiento de modelos, es que antes de generar una respuesta, el modelo recupera información relevante de una base de conocimiento con varios orígenes, que puede estar formada por un conjunto de documentos. Esta etapa mejora la precisión del modelo al basar las respuestas en datos actualizados y específicos.
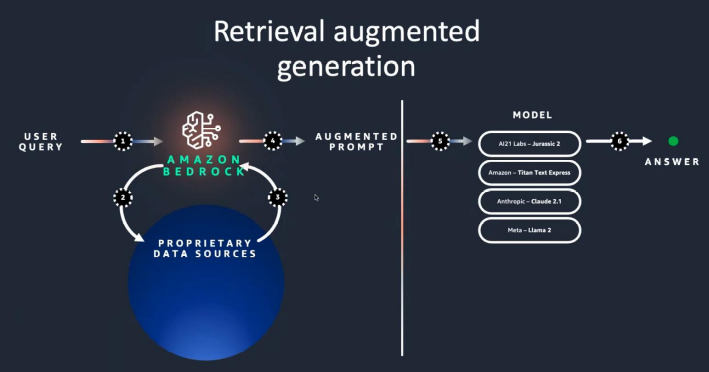
Una vez recuperados los datos necesarios, Bedrock los utiliza para generar respuestas más precisas y contextualmente relevantes respecto a los documentos incluidos en la base de conocimientos. La combinación de recuperación y generación ayuda a mitigar el problema de la alucinación en los modelos de lenguaje, donde el modelo inventa información que no estaba incluida en el entrenamiento ni por datos reales.
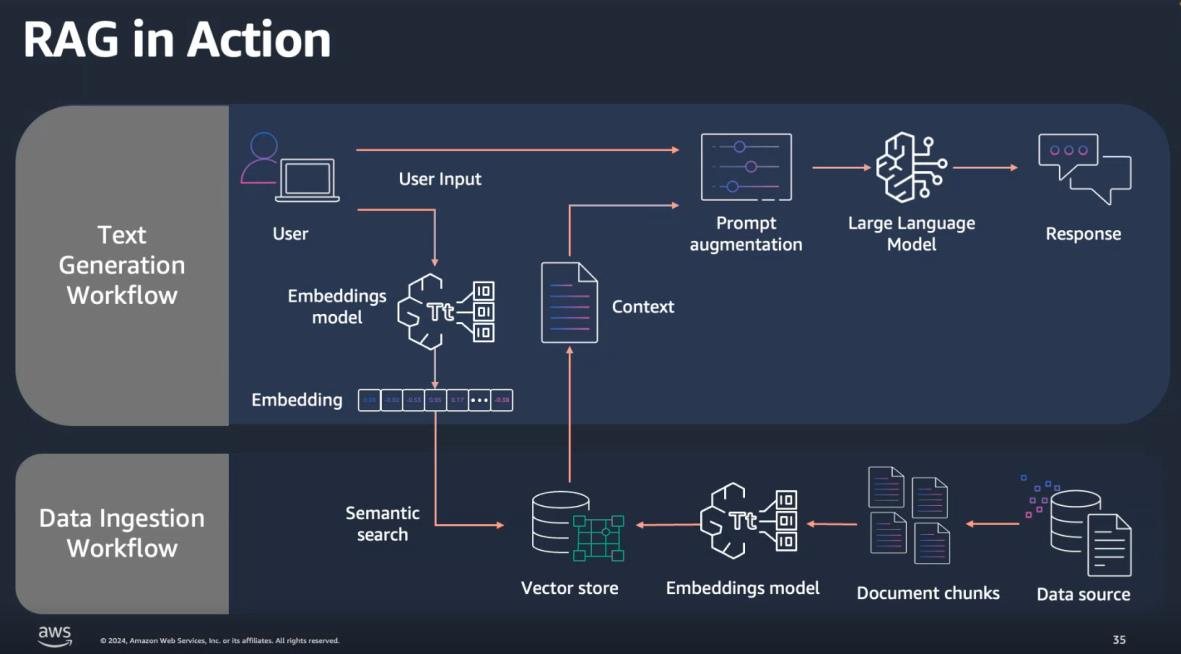
En resumen, RAG mejora la precisión y relevancia de las respuestas del chatbot al combinar la recuperación de información (utilizando técnicas de fragmentación y búsqueda en bases de datos vectoriales) con la generación de texto.
AWS Bedrock ofrece una implementación sencilla de esta técnica y puede recuperar información relevante de los archivos PDF antes de generar una respuesta, asegurando que las respuestas sean precisas y estén basadas en la documentación actualizada que le hemos proporcionado, aumentando significativamente el nivel de personalización del modelo.
Manejo eficiente de las bases de conocimiento mediante bases de datos vectoriales (embeddings):
Una base de conocimientos es una colección estructurada de información sobre un dominio específico. Está organizada de manera que pueda ser consultada y utilizada para responder preguntas o realizar tareas relacionadas con ese dominio. Esta base de conocimiento se puede almacenar en lo que se conoce como base de datos vectorial.

Una base de datos vectorial, como su nombre indica, es un tipo de base de datos diseñada para almacenar y consultar datos vectoriales, donde cada entrada está representada por un vector. Esta representación es útil para consultas basadas en similitud o distancia entre vectores, clave en el proceso de aplicar RAG.
Estos vectores almacenados se calculan en base a los datos de entrada mediante modelos de embedding. Dado que las redes neuronales no aceptan palabras como entrada sino tensores, estas palabras deben transformarse en una representación numérica que el modelo entienda, esta transformación se hace a través de lo que se conoce como embedding.
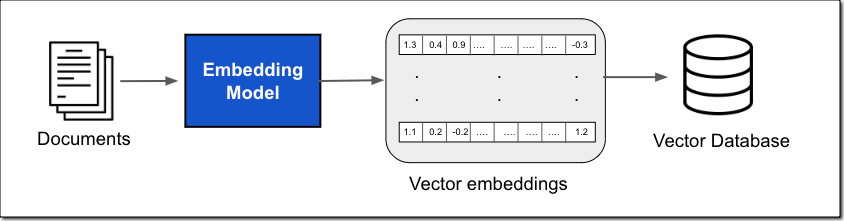
Este sería el proceso típico:
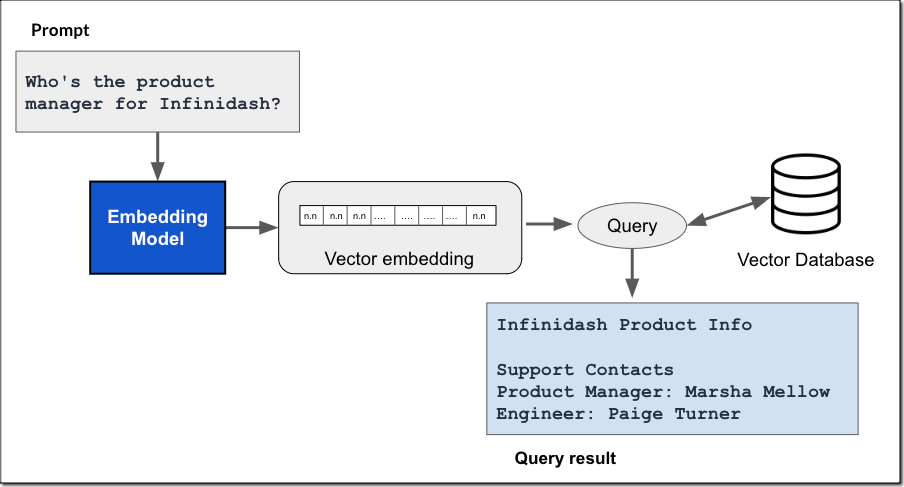
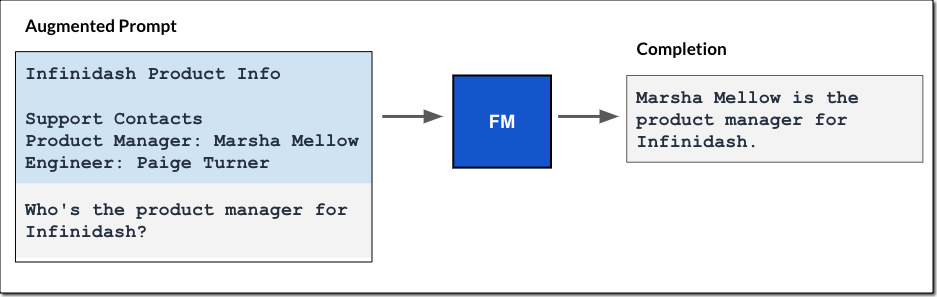
En definitiva, AWS Bedrock puede procesar e indexar automáticamente los documentos PDF que se inserten en la base de conocimientos, facilitando la recuperación rápida de información relevante.
El chatbot puede acceder rápidamente a la información necesaria para responder preguntas específicas, mejorando la experiencia del usuario y reduciendo el tiempo de respuesta. Solo nos tendríamos que asegurar de actualizar la información de los archivos PDF cuando corresponda para evitar un fenómeno que se conoce como data-drift.
Un concepto que se define como una variación en los datos de producción con respecto a los datos que se utilizaron para probar y validar el modelo antes de implantarlo en producción. Lo que provoca un desfase en las respuestas del modelo, ya que quedan anticuadas.
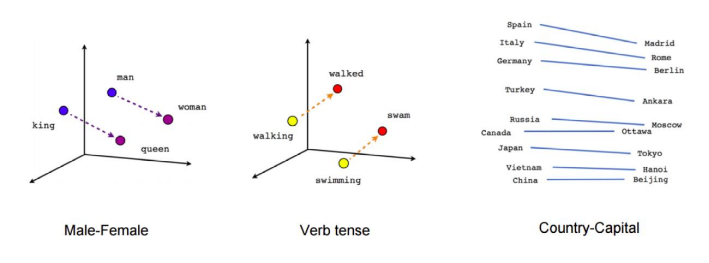
Un embedding de palabras o word embedding es una representación vectorial de una palabra. Estos vectores capturan características y relaciones semánticas así como similitudes entre palabras según la distancia vectorial entre ellas. Los más conocidos son Word2Vec, una familia de modelos de embeddings o GloVe. Aunque Amazon nos proporciona su propia familia de modelos de embeddings conocida como Titan.
Agentes
Un agente de inteligencia artificial es una entidad de software que puede interactuar con su entorno, recopilar datos y utilizarlos para realizar tareas definidas de forma autónoma a fin de cumplir unos objetivos predeterminados.

En Bedrock se pueden crear y configurar agentes autónomos para el caso de uso. Un agente ayuda a sus usuarios finales a completar acciones basadas en datos de la organización y entradas del usuario.
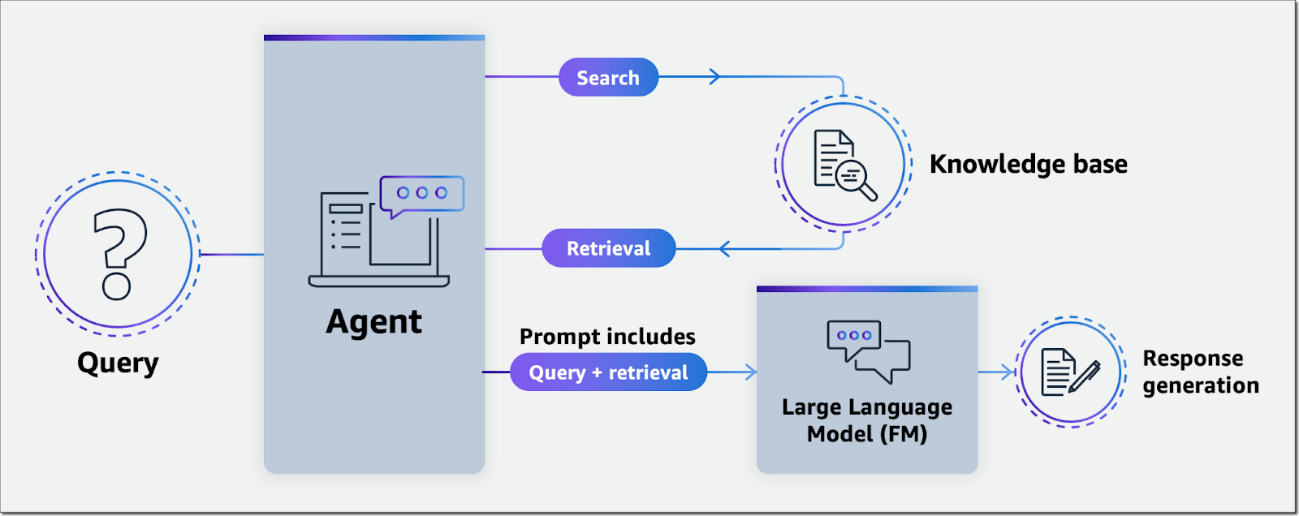
Los agentes orquestan interacciones entre modelos de base (FM), fuentes de datos, aplicaciones de software y conversaciones de usuario. Además, los agentes llaman automáticamente a las API para realizar acciones e invocan bases de conocimiento para complementar la información para estas acciones.

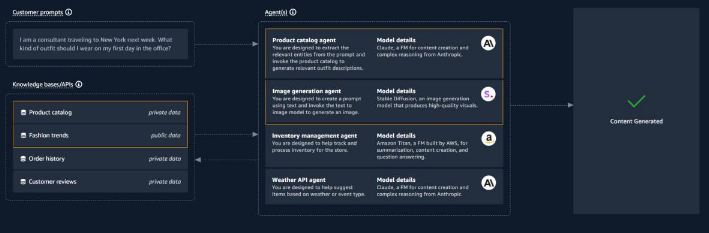
En la figura de arriba, se muestran 4 agentes que cada uno interactúa con un modelo diferente para mejorar la calidad y relevancia de las respuestas. Este sería un ejemplo, que se puede probar en la demo pública:
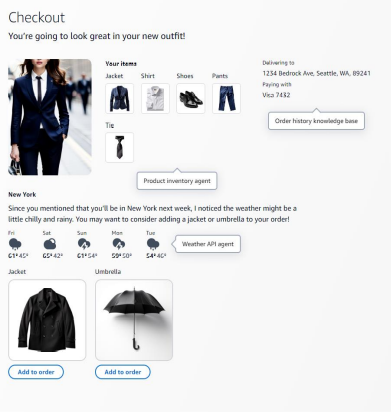
2. Ejemplos de casos de uso
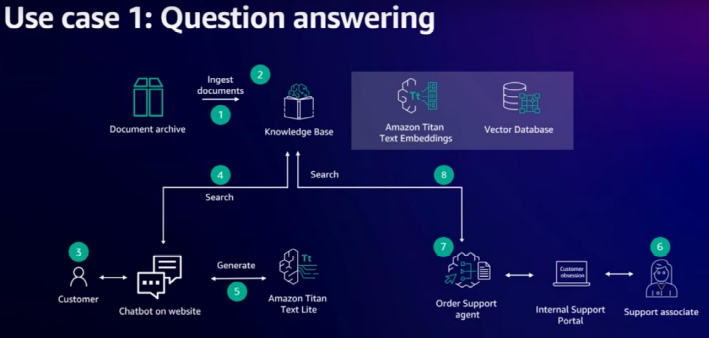
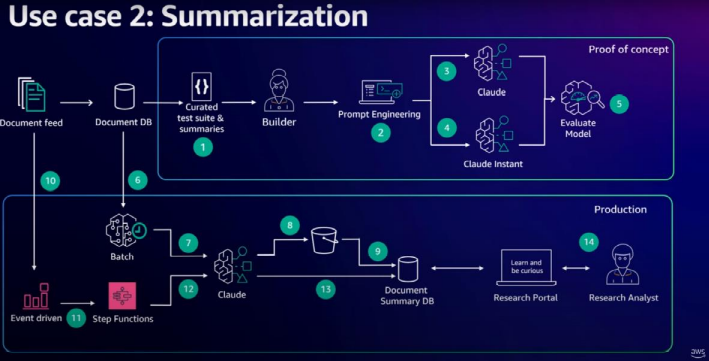
3. Conclusión
En conclusión, AWS Bedrock proporciona una plataforma robusta y gestionada que facilita la implementación de un chatbot utilizando una base de conocimiento propia. Combinando la técnica RAG para mejorar la precisión de las respuestas y beneficiándose de una infraestructura escalable y segura. Esto permite a las empresas centrarse en mejorar la experiencia del usuario y la precisión de la información proporcionada por el chatbot, sin preocuparse por la gestión de la infraestructura subyacente.